EfficientNetV2: Smaller Models and Faster Training (ICML 2021)
EfficientNetV2: Smaller Models and Faster Training (ICML 2021), PDF
Mingxing Tan, Quoc V. Le
오늘 살펴볼 논문은 EfficientNetV2입니다. Google Brain에서 2년 전 공개한 EfficientNet은 다른 모델에 비해 빠른 학습 속도와 높은 성능으로 주목을 받아 현재까지 최고의 성능으로 널리 사용되었습니다. EfficientNet 관련 리뷰는 제가 작성한 이곳을 참고하시면 좋을 것 같습니다. 그리고 최근 Google Brain에서 학습 속도와 정확도를 개선하여 기존 모델의 성능을 크게 상회하는 EfficientNetV2(2021)를 발표했습니다. 본 논문을 전체적인 흐름에 따라 리뷰해보겠습니다.
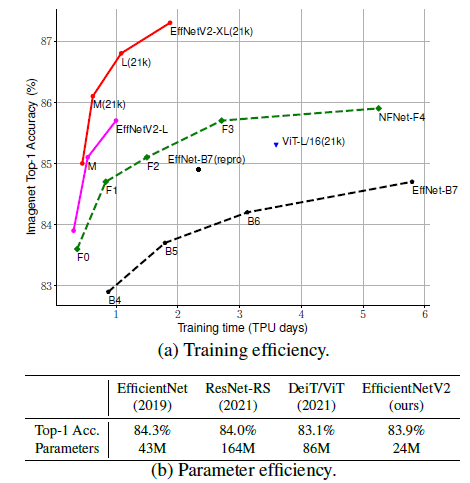
Introduction
논문에서는 기존의 EfficientNet(이하 EfficientNetV1)에서 훈련을 느리게 하는 병목 현상을 3가지로 설명합니다. (1) 큰 이미지로 학습을 하면 학습 속도가 느립니다. (2) Depthwise convolution은 초기 레이어에서 학습 속도가 느립니다. (3) 모든 단계를 동일하게 scaling하는 것은 최선의 방법이 아닙니다. 따라서 EfficientNetV2(2021)는 이 3가지를 해결하기 위해서 adaptive regularization을 사용한 progressive learning, fused-MBConv, non-uniform scaling 방법을 소개합니다.
또한 본 논문에서 3가지 컨트리뷰션을 주장합니다.
-
더 작고 빠른 새로운 모델의 EfficientNetV2를 소개합니다. training-aware NAS와 scaling을 통해 발견된 EfficientNetV2는 훈련 속도와 파라미터 효율성 모두에서 이전 모델을 능가합니다.
-
우리는 이미지 크기에 따라 정규화를 적응적으로 조정하는 Progressive learning을 제안합니다. 우리는 그것이 학습속도를 높이고, 동시에 정확도를 향상시킨다는 것을 보여줍니다.
-
ImageNet, CIFAR, Cars 및 Flowers 데이터셋에서 기존 연구 모델보다 최대 11배 더 빠른 훈련 속도와 최대 6.8배 더 나은 파라미터 효율성을 보여줍니다.
그럼 어떻게 학습 속도와 정확도, 그리고 파라미터 효율성을 개선하였는지 중점적으로 살펴보겠습니다.
EfficientNetV2 Design
앞서 말씀드린 EfficientNetV1(2019)에서의 학습 병목 현상을 3가지를 연구하고 개선하는 방법을 소개합니다.
(1) Training with very large image sizes is slow
- 큰 이미지로 학습을 하면 학습 속도가 느립니다.
EfficientNetV1(2019)의 큰 이미지 크기는 상당한 메모리 사용량을 가져옵니다. GPU/TPU의 메모리 총량은 고정되어 있기 때문에 더 작은 배치 크기로 학습하여야 하므로 훈련 속도가 크게 느려집니다. Table 2를 보면 더 작은 이미지 크기는 적은 연산량을 가져오고 더 큰 배치 크기를 가능하게 하기 때문에 학습 속도를 2.2배까지 향상시킵니다. 특히, 학습에 더 작은 이미지 크기의 사용은 더 좋은 정확도를 가져옵니다.

따라서 개선된 학습 방식인 이미지 크기와 정규화를 점진적으로 조정하는 Progressive learning에 대해 더 알아보겠습니다.
Progressive learning
이미지 크기는 모델의 학습 시간에 중요한데, 이미지 크기를 변형시켜 학습하는 다양한 방법들이 있지만 종종 정확도의 저하를 야기하기도 합니다. 저자는 여기서 정확도의 저하가 불균형한 정규화에서 비롯된 것이라 가정합니다. 즉, 다른 이미지 크기를 학습할 때 고정된 정규화를 사용하는 것이 아니라 이미지 크기에 따라서 정규화의 강도도 조정해야 된다는 것 입니다.

위 테이블을 보면 이 가설을 검증하기 위해 모델을 다른 이미지 사이즈와 데이터 augmentation으로 학습시킨 결과입니다. 이미지 사이즈가 작을 때는 약한 augmentation에서 가장 성능이 좋고 반대로 이미지 사이즈가 크면 강한 augmentation에서 성능이 좋은 걸 확인할 수 있습니다. 즉 이 논문에서 저자는, 동일한 네트워크에서도 이미지 크기가 작을수록 네트워크 용량이 작아지므로 정규화가 더 약해질 필요가 있다고 주장합니다. 반대로 이미지 크기가 클수록 더 큰 용량에서 더 많은 연산을 수행하므로 과적합에 취약하기 때문에 더 강력한 정규화가 필요하다고 말합니다.

따라서 본 논문에서는 모델을 학습 시킬 때 이미지 사이즈에 따라서 조정된 정규화를 사용합니다. 위 그림은 이 논문의 progressive learning 학습 과정을 보여줍니다. 모델의 초기 학습 단계는 네트워크가 간단한 표현을 쉽고 빠르게 배울 수 있도록 더 작은 이미지와 약한 정규화로 네트워크를 학습합니다. 그리고 점차 이미지 크기를 늘리면서 더 강력한 정규화로 학습을 어렵게 합니다.

제안하는 progressive learning 학습은 기존의 모든 정규화에 호환되나, 본 논문에서는 다음 세 가지의 정규화에 대해서만 주로 다룹니다.
- Dropout (Srivastava et al., 2014): 채널을 무작위로 삭제하여 co-adaptation을 줄이는 네트워크 수준 정규화
- RandAugment (Cubuk et al., 2020): 이미지별 데이터 증가
- Mixup (Zhang et al., 2018): 교차 이미지 데이터 증가
(2) Depthwise convolutions are slow in early layers but effective in later stages
- Depthwise convolution은 초기 레이어에서 학습 속도가 느립니다.
EfficientNetV1(2019)의 또 다른 병목은 광범위한 depthwise convolution에서 발생합니다. Depthwise convolutions은 MobileNetV1과 Xception에서 제안된 방법으로 효과가 입증되어 최신 모델에 이용하고 있습니다. Depthwise convolution은 Conv 연산량을 줄여 제한된 연산량 아래에서 더 많은 filter를 사용할 수 있는 이점이 있지만 modern accelerator를 사용하지 못하기 때문에 학습 속도가 느립니다. 따라서 Stage1-3에서는 MBConv(Mobile inverted bottleneck convolution) 대신에 Fused-MBConv를 사용합니다. Fused-MBConv는 MBConv의 1x1 conv + 3x3 depthwise conv 대신에 하나의 3x3 conv를 사용하는 것입니다. 모든 stage에 Fused-MBConv를 적용하니 오히려 학습 속도가 느려져 초기의 stage에만 Fused-MBConv를 사용합니다.
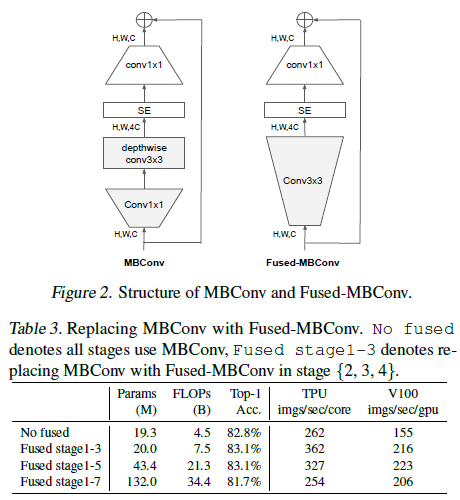
(3) Equally scaling up every stage is sub-optimal
- 모든 단계를 동일하게 확장하는 것은 최선이 아닙니다.
EfficientNetV1(2019)은 depth, width, resolution의 3가지 scaling factor를 동시에 고려하는 compound scaling방법으로 모델 확장하는데, 모든 stage를 동일하게 확장했습니다. 하지만 stage가 학습 속도에 기여하는 정도가 다르다고 주장합니다. 따라서 stage가 증가할 수록 layer가 증가하는 정도를 높이는 non-uniform scaling 전략을 제안합니다. 이 때 증가하는 정도는 heuristic하게 정합니다. 또한 compound scaling에서 최대 이미지 크기를 제한하는데, progressive learning은 학습이 진행될 수록 입력 이미지 크기가 커지므로 메모리 사용량이 커져 학습 효율 감소를 최소화하기 위해서입니다.
EfficientNetV2 Architecture
EfficientNetV1(2019)와 마찬가지로 AutoML 방법인 신경망 아키텍쳐 탐색 (Neural Architecture Search; NAS) 기술을 사용하여 네트워크 구조를 탐색합니다. 저자는 이전 NAS를 기반으로 하되, 정확도, 파라미터 효율성 및 훈련 효율성을 공동으로 최적화하는 것을 목표로 합니다. EfficientNet을 백본으로 사용하여 이 과정을 통해 찾은 EfficientNetV2-S의 아키텍쳐는 아래와 같습니다.
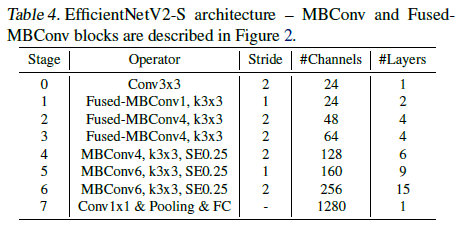
기존 EfficientNetV1(2019)과 주요 차이점은 다음과 같습니다.
- MBConv와 새로 추가된 fused-MBConv를 초기 레이어에 사용합니다.
- 메모리 접근 비용을 줄이기 위해 MBConv에 대해서 작은 expansion ratio를 사용합니다.
- 3x3의 작은 커널 사이즈를 사용하고 그에 따른 receptive field 감소를 보완하기 위해서 더 많은 레이어를 사용합니다.
- 파라미터와 메모리 접근 비용을 줄이기 위해 기존의 EfficientNetV1에서의 마지막 stride-1 단계를 완전히 제거합니다.
EfficientNetV2 scaling
EfficientNetV2-S 모델을 기존의 compound scaling에 몇가지 추가적인 최적화를 더하여 EfficientNetV2-M/L 모델로 확장했습니다.
추가된 최적화
- 최대 추론 이미지 크기를 480으로 제한합니다. (너무 큰 이미지는 비싼 메모리와 학습 속도 비용을 발생시킴)
- 뒤쪽 단계(stage 5, 6)에 점진적으로 더 많은 layer를 추가합니다. (런타임 비용없이 네트워크 용량을 늘리기 위해서)
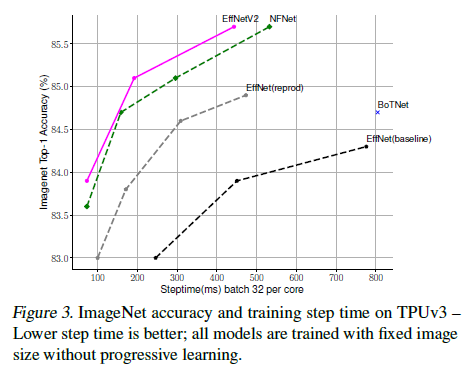
Performance Results
기존 ConvNet과 비교한 결과는 다음 표에 나와있습니다.
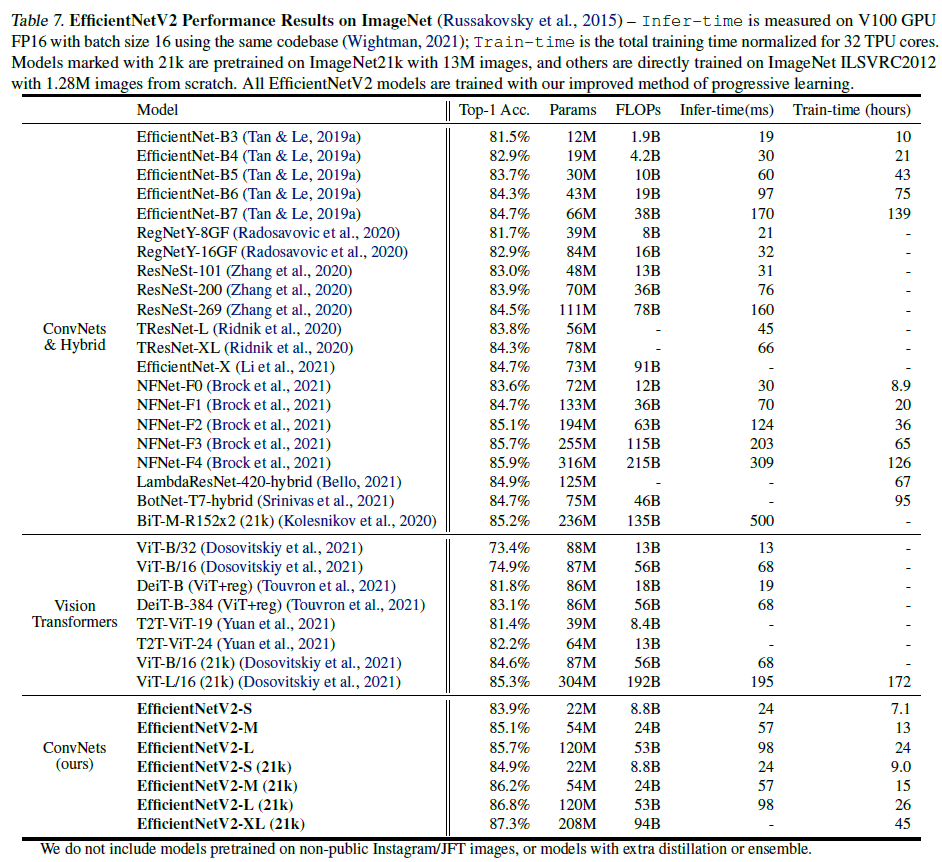
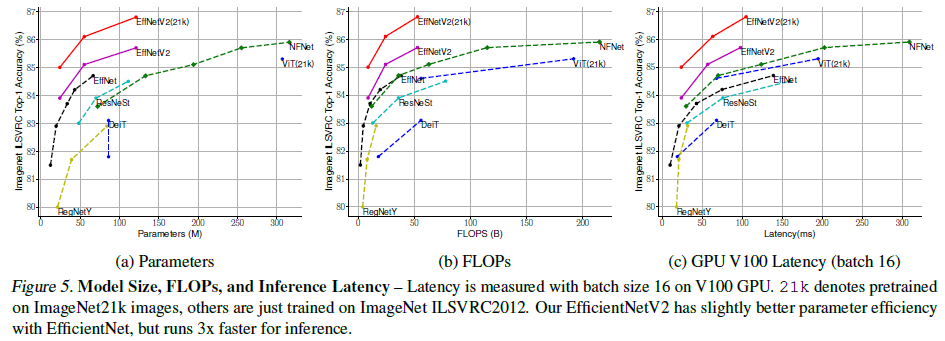
Figure 5를 보면 동일 파라미터 수와 FLOPS수에서 기존 ConvNet보다 더 높은 성능을 보이고 있습니다. 기존 ConvNet에 비해 비슷한 정확도를 보이면서 파라미터 수와 FLOPS 수를 훨씬 절약한 것을 알 수 있습니다. 이 외에도 다양한 실험 결과들은 논문에서 추가로 확인하실 수 있습니다.
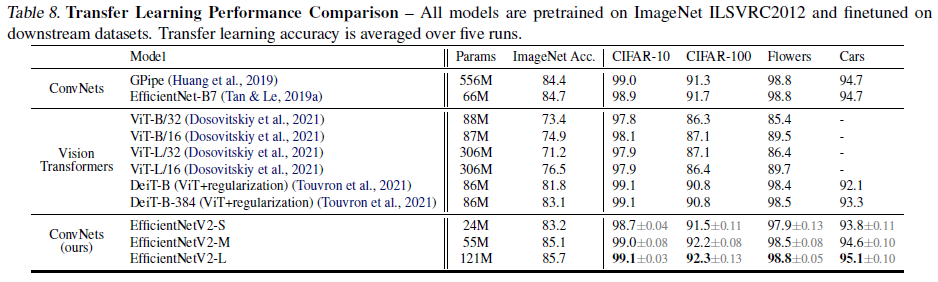
EfficientNetV1에서 compound scaling 방법이 휴리스틱한 계수에 크게 의존한다고 지적되었던 부분이 여전히 개선되지 않은 부분은 아쉬웠습니다. 그러나 기존 EfficientNetV1의 문제점을 개선하면서 더 월등한 성능과 동시에 학습 속도와 파라미터 수를 동시에 절약한 점이 인상깊습니다.