EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (ICML 2019)
들어가며
ICML 2019에서 발표된 “EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks“은 현재(‘21년 9월)까지도 인용수 3천회 이상을 돌파하며 현재까지도 엄청난 인기를 가진 논문입니다. Image Classification 분야에서 월등한 성능과 빠른 학습으로 큰 반향을 가져왔습니다. 본 논문의 주요 아이디어와 결과 위주로 살펴보겠습니다.
Convolutional neural networks(CNNs)은 일반적으로 고정된 리소스 비용으로 개발된 다음, 더 많은 리소스를 사용할 수 있게 되면 정확도를 높이기 위해 확장(scale up)됩니다. 예컨대 ResNet (He et al, 2016) 은 ResNet-18에서 layer를 ResNet-200까지 확장하고 GPipe (Huang et al, 2018)는 기준 CNN을 4배 확장하여 84.3%의 ImageNet top-1 정확도를 달성했습니다. 기존의 모델 확장은 CNN의 깊이 또는 너비를 임의로 늘리거나 훈련에 더 큰 이미지 해상도를 사용하는 것입니다. 이러한 방법을 사용하면 정확도가 향상되지만 수동 조절이 필요하며 최상의 성능을 보여주기는 어렵습니다. 따라서 더 나은 정확도와 효율성을 위해 CNN을 확장하는 좋은 방법은 무엇인지 살펴봅니다.
본 논문에서는 모델 확장 방법(Model scaling method)로 Compound Model Scaling이라는 compound coefficient를 사용하는 방법을 제안합니다. 너비(width), 깊이(depth), 해상도(resolution)와 같은 네트워크 차원 중 1가지 임의로 확장하는 기존 방식과 달리, 이 방법은 고정된 계수를 사용하여 각 차원을 균일하게 확장합니다. 이 새로운 확장 방법과 AutoML의 발전에 힘입어 EfficientNet이라는 더 작고 더 빠른 모델을 개발했다고 합니다.
Compound Model Scaling: A Better Way to Scale Up CNNs
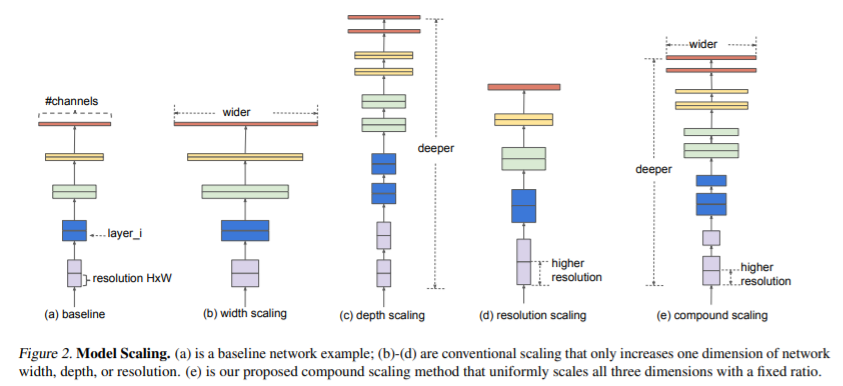
네트워크 확장 효과에 대해 이해하기 위해서 모델의 다른 차원의 확장 효과에 대해 연구하였습니다. 채널의 개수를 늘리는 width scaling, layer의 개수를 늘리는 depth scaling, input image의 해상도를 높이는 resolution scaling이 있습니다. ResNet (He et al., 2016)은 depth를 통해 모델을 확장하는 대표적인 모델이며 MobileNet (Howard et al., 2017)은 width를 조절하여 모델을 확장하는 대표적인 모델입니다. 각각의 차원을 개별적으로 확장하면 모델의 성능이 향상되지만, 모든 차원의 균형을 맞추어 동시에 확장하는 것이 전반적인 성능을 더 잘 향상시킨다는 것을 논문에서 실험으로 보여줍니다. 즉 모델을 확장하기 위해 3가지 차원을 함께 고려하는 Compound scaling 방법을 제안합니다.
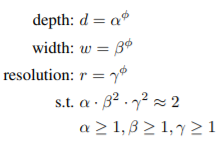
$\alpha$, $\beta$, $\gamma$ 는 grid search를 통해 고정 리소스 제약 조건(e.g., 2배 더 많은 FLOPS)에서 위 관계식을 만족하는 계수를 찾습니다. 여기서 width에 해당하는 $\beta$와 resolution에 해당하는 $\gamma$가 제곱인 이유는 FLOPS에 가로, 세로로 각각 곱해지기 때문에 제곱 배 증가하기 때문입니다. 처음에는 $\pi$를 1로 두어 계수를 찾습니다. 논문에서는 $\alpha=1.2$, $\beta=1.1$, $\gamma=1.15$를 사용했습니다. 그런 다음 $\pi$를 늘려준 계수를 적용하여 baseline 네트워크를 원하는 타겟 모델 사이즈 또는 계산 비용에 맞게 확장시킵니다.
이 Compound scaling 방법은 기존 scaling 방법에 비해 MobileNet(+1.4%) 및 ResNet(+0.7%)로 모델의 정확도를 향상시켰습니다.
EfficientNet Architecture
모델 확장(model scaling)은 baseline 네트워크에 크게 좌우됩니다. 따라서 정확도와 효율성(FLOPS)을 모두 최적화하는 AutoML MNAS 프레임워크를 사용하여 Neural Architecture Search(NAS) 방법을 통해 새로운 baseline 네트워크를 개발했습니다. 그 아키텍쳐는 mobile inverted bottleneck convolution(MBConv)를 사용하는데, 이는 MobileNetV2 및 MnasNet과 유사한 구조입니다.
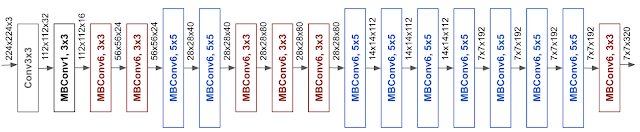
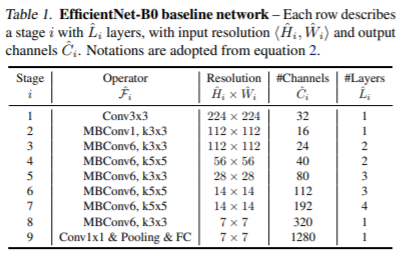
EfficientNet Performance
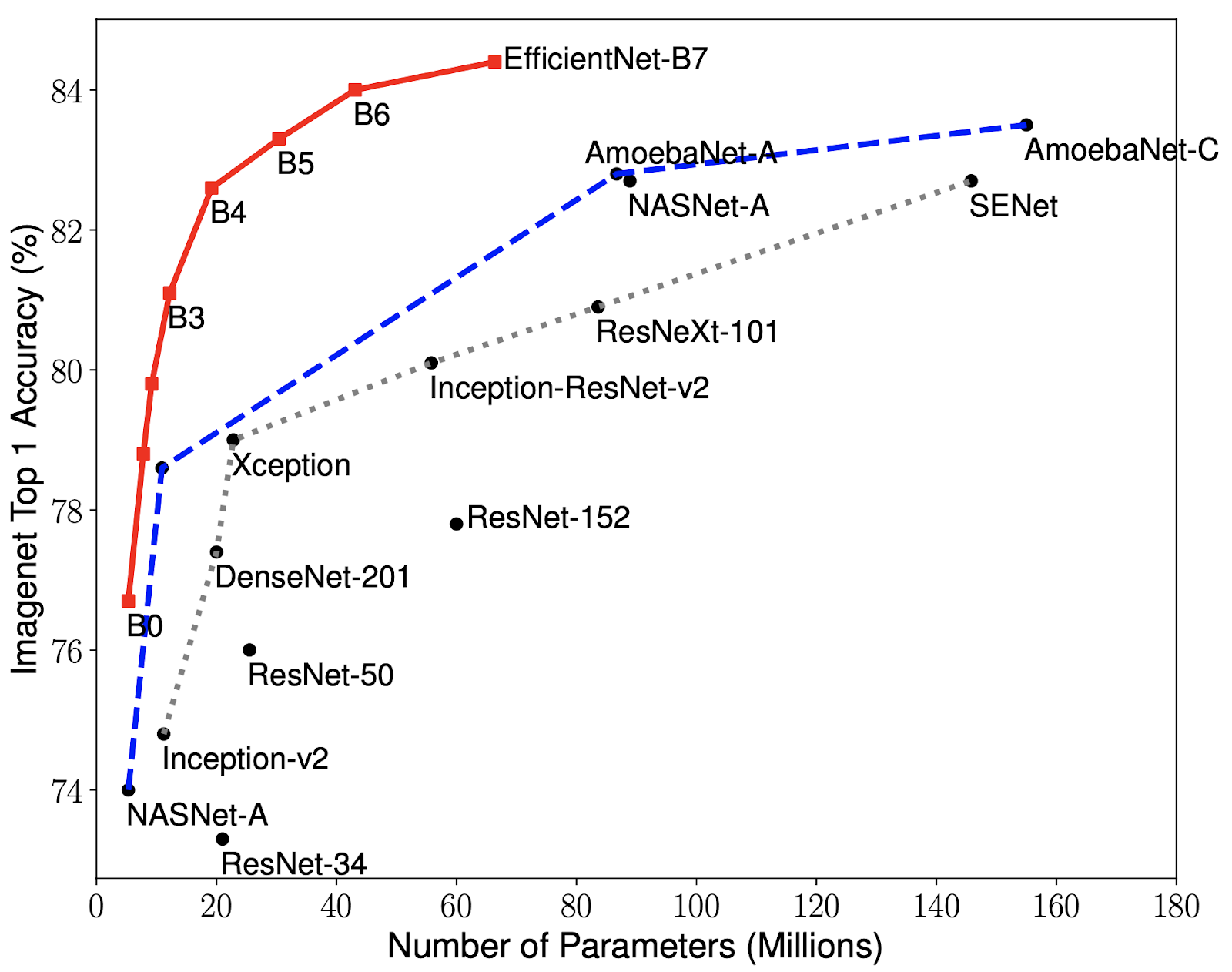
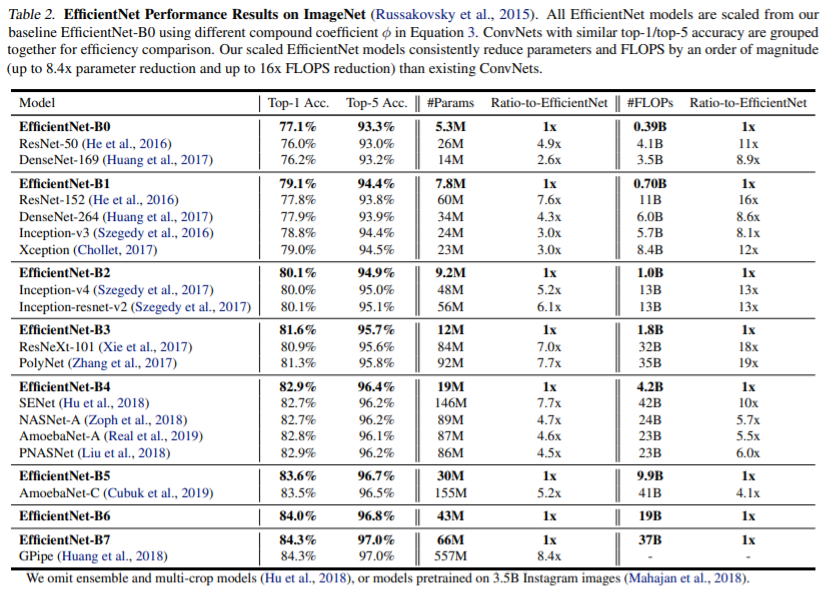
EfficientNet을 ImageNet의 다른 기존 CNN과 성능을 비교한 결과입니다. EfficientNet 모델은 다른 모델에 비해 더 높은 정확도와 더 나은 효율성을 달성하여 파라미터 크기와 FLOP를 수십 배 줄인 것을 확인할 수 있습니다. EfficientNet-B7은 ImageNet에서 top-1 정확도 84.4%, top-5 정확도 97.1% 를 도달하는데 CPU 추론에서 8.4배 더 작고 속도는 6.1배 더 빠릅니다. 특히 널리 사용되는 ResNet-50과 비교하면 EfficientNet-B4와 비슷한 FLOP을 사용하지만, top-1 정확도가 76.3%에서 82.6%으로 크게 향상됐습니다.
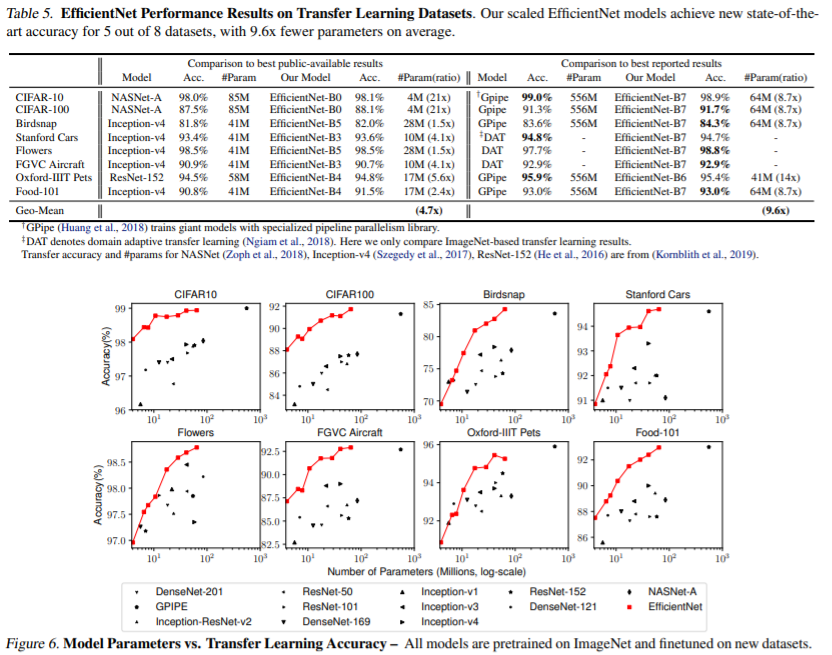
EfficientNet이 가장 유용하기 위해서는 다른 데이터 세트로도 전이해야 합니다. 이를 평가하기 위해 널리 사용되는 8개의 transfer learning 데이터 세트에서 EfficientNet을 시험한 결과가 위와 같습니다. EfficientNets는 CIFAR-100(91.7%), Flowers(98.8%)와 같은 8개 데이터 세트 중 5개에서 SOTA 정확도를 달성면서 게다가 이 때 파라미터 수는 최대 21배 더 적습니다. EfficientNet이 전이 또한 잘 된다는 것을 의미합니다.
Conclusion
모델 효율성에 상당한 개선과 함께 압도적인 성능 향상을 제공한 EfficientNet이 미래의 컴퓨터 비전 태스크를 위한 새로운 토대 역할을 할 수 있을 것으로 기대합니다.
References
[1] EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (ICML 2019)
[2] Google AI Blog