YOLOv1: You Only Look Once: Unified, Real-Time Object Detection
1. 들어가며
이번 포스팅은 Object Detection에서 가장 유명한 논문이자 Real-Time Object Detection에 한 획을 그은 논문에 대해 리뷰해보겠습니다. 줄여서 흔히 YOLO라고 불리는 CPVR 2015에서 발표된 “You Only Look Once: Unified, Real-Time Object Detection“은 현재까지 인용수 1만 8천회에 달합니다.

YOLO를 실제로 적용한 모습입니다. 꽤 정확하지만 중간에 사람을 비행기로 잘못 분류한 모습도 보입니다. YOLO 등장 이전의 Object Detection은 대표적으로 R-CNN과 DPM 있는데, Region Proposal을 기반으로 높은 정확도를 가지는 모델입니다. 그러나 처리 시간이 오래 걸리기 때문에 실시간 탐지가 어려워 실생활에 적용되기 어려웠습니다. 반면에 YOLO는 정확도를 개선하기 보다는 정확도는 기존과 비슷하게 유지하면서 더 많은 양의 이미지를 한번에 빠르게 처리할 수 있는 Real-Time Object Detection를 목표로 합니다. 저자 Joe Redmon은 2015년 YOLO 발표 후 업데이트된 YOLO 버전 3까지 발표하였습니다.
특징
본 논문의 제목과 마찬가지로 특징을 아래 세 가지로 정리할 수 있습니다.
-
You Only Look Once : 이미지 전체를 딱 한번만 본다
기존 모델인 R-CNN은 이미지를 일정한 규칙으로 여러장 쪼개고 그 이미지들을 CNN에 통과시키기 때문에 이미지를 여러번 봐야합니다. 그러나 YOLO를 이미지 전체를 CNN에 단지 한번 통과시킵니다.
-
Unified : 통합된 모델을 제안한다
다른 모델은 객체의 위치를 찾고, 그 후에 찾은 위치를 기반으로 분류를 진행하는 부분이 결합된 형식의 모델입니다. 그러나 YOLO는 하나의 뉴럴 네트워크로 전부 처리합니다.
-
Real-Time Object Detection : 실시간 객체 탐지가 가능하다
YOLO는 45 FPS의 성능으로 Fast R-CNN이 0.5 FPS를 가진 것에 비해 90배나 빠릅니다. 즉 영상의 물체를 부드럽게 구분할 수 있을 정도입니다.
2. YOLO Detection System

어떻게 이미지를 한번에 처리할 수 있는지 YOLO의 구조를 살펴보겠습니다. 위 그림은 YOLO의 대략적인 구조입니다. 448x448로 리사이즈된 이미지를 단 1개의 CNN에 통과시킵니다. 이전 모델과 달리 1-step으로 처리하는 이 간단한 구조는 YOLO가 이미지를 그리드로 나누어 Localization과 Classification을 동시에 CNN으로 처리하기 때문입니다.
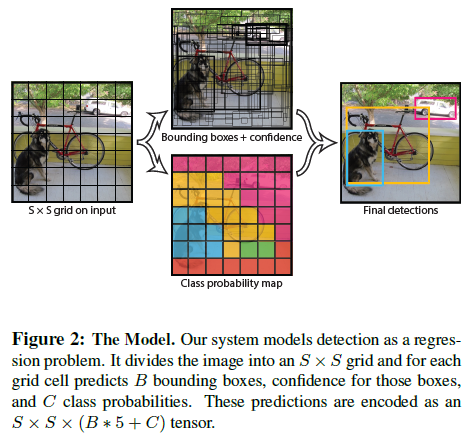
먼저 이미지를 SxS 그리드 셀로 나눕니다. 그리고 각각의 그리드에서 물체가 있을 만한 영역을 B개의 Bounding Box로 예측합니다. 이때 (x, y)는 Bounding Box의 중심점 좌표이고, (w, h)는 너비와 높이로 표현합니다. 그리고 그 박스의 $Confidence=Pr(Object)*IOU^{truth}_{pred}$로 나타내는데 해당 그리드에 물체가 있을 확률과 예측한 박스와 Ground truth 박스와 겹치는 정도를 나타내는 IOU를 곱해 계산합니다.
각각의 그리드마다 C개의 클래스의 조건부 확률을 구합니다.
\[Pr(Class_{t}|Object)*Pr(Object)*IOU^{truth}_{pred}=Pr(Class_{t})*IOU^{truth}_{pred}\]본 논문에서 PASCAL VOC에 그리드 수인 S=7, 바운딩 박스의 개수는 B=2, 그리고 20개의 label이 있으므로 C=20를 사용했다고 합니다. 따라서 최종 예측 결과는 7x7x30 텐서입니다.
3. Network Design

YOLO의 네트워크 구조를 살펴보겠습니다. YOLO는 24개의 Convolutional Layer(Conv Layer)와 2개의 Fully-Connected Layer(FC Layer)로 연결된 구조입니다.
Pre-trained Network
위 그림은 YOLO의 네트워크 구조를 보여줍니다. 앞부분의 20개의 Conv Layer는 Pre-trained Network로 GoogLeNet을 이용하여 ImageNet 1000-class dataset을 사전에 학습한 결과를 Fine-tuning한 네트워크입니다. 원래 ImageNet의 데이터셋은 224x224의 크기지만 Object Detection에서는 경계선이 흐릿한 이미지의 학습이 더 잘된다고 하여 이미지를 448x448로 2배 확대한 이미지를 입력 이미지로 받습니다. 그리고 뒤에 4개의 Conv Layer는 목적에 맞게 학습시킵니다.
Reduction Layer
몇몇의 Conv Layer는 1x1를 사용하고 있는데 이는 Reduction Layer로 번갈아가면서 피쳐 맵의 깊이를 줄입니다. 네트워크는 깊을 수록 더 많은 특징을 학습하여 성능이 높습니다. 그러나 그만큼 수행 시간이 오래걸리기 때문에 YOLO는 연산량 감소를 위해 Reduction Layer를 사용한 GoogLeNet의 기법을 사용하였습니다.
Training Network
마지막 2개의 FC Layer는 Conv Layer에서 나온 피쳐맵을 가지고 Bounding Box를 예측하고 Class의 확률을 구하는 부분입니다. Conv Layer의 마지막은 (7, 7, 1024)의 모양을 가진 텐서입니다. 이 텐서를 1차원으로 편 다음 2개의 Linear regression의 형태인 FC Layer를 통해 네트워크의 최종 아웃풋은 (7, 7, 30)이 됩니다. (B=2, S=7, C=20 가정) 각 그리드 별로 2개의 Bounding Box의 정보 5가지(x, y, w, h, Confidence)가 있으므로 10개가 되고, Class가 20개이기 때문에 각 Class별 확률값이 20개가 있기 때문에 총 30개의 값이 있는 모습입니다.
7x7x2개의 Bounding Box가 나오는데 겹치는 Bounding Box 중 IOU가 높은 박스를 선택하는 Non-Maximum Suppression을 통하여, 최종 bounding box의 Location과 Class를 결정합니다.
4. Loss Fuction
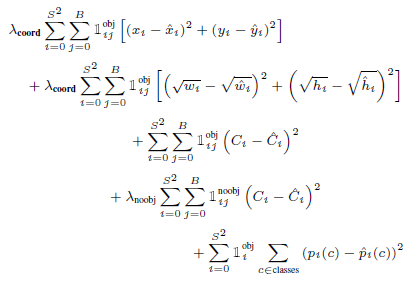
YOLO의 Loss Function의 전체는 위와 같습니다. 이를 Localization Loss, Confidence Loss, Classification Loss의 3부분으로 나누어 보겠습니다.
Localization Loss
Bounding Box의 위치와 크기에 대한 Loss를 측정하는 부분입니다. 물체로 탐지된 부분의 Bounding Box만 계산합니다.
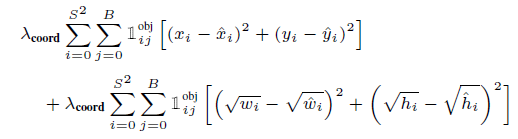
최종 예측된 바운딩 박스에 객체가 존재하는 경우($1_{ij}^{obj}$)를 찾아내어 x, y 좌표, w, h 예측 값과 Ground Truth의 값의 차를 구해 모두 더해줍니다. 이 때 sum-squared error를 사용하여 optimize하기 쉽습니다.
그러나 평균적인 정확도를 높여야하는 모델의 목표에 맞지 않으므로 Localization Error와 Classification Error의 weight를 다르게 줍니다. 특히 Localization Error에 Confidence Error보다 더 높은 패널티를 줌으로써 박스 안에 물체가 없는 경우는 Confidence score를 0으로 만들 수 있습니다. 논문에서는 $\lambda_{coord}=5$로 주었습니다.
Confidence Loss
Confidence score에 대한 Loss를 측정합니다. 이때 해당 셀에 객체가 존재하는 경우와 해당 셀에 객체가 존재하지 않는 경우($1_{ij}^{noobj}$)의 패널티가 다릅니다.
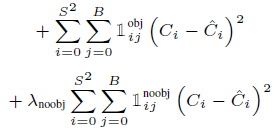
이미지의 각 그리드에는 객체보다 배경이 더 많기 때문에 이러한 imbalance를 교정하기 위해 배경을 탐지한 경우는 Bounding Box 학습에 영향을 미치지 않도록 ($\lambda_{noobj}=0.5$) 로 더 작게 줍니다.
Classification Loss
객체를 탐지한 경우, 조건부 확률 ($\hat{p}_{i}(c)$)로 classification에 대한 Loss를 측정합니다.
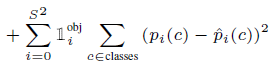
5. Performance
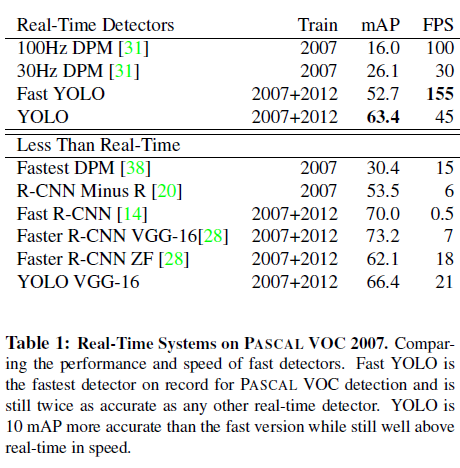
YOLO의 빠른 버전으로 9개의 Conv Layer를 가지는 Fast YOLO는 FASCAL VOC 탐지에서 기존 모델보다 약 2배 정도 더 나은 mAP를 보여주며 가장 빠른 FPS를 보여주고 있습니다. 또한 YOLO도 다른 DPM, R-CNN 모델과 어느정도 비슷한 정확도를 유지하면서 가장 빠른 FPS로 빠르고 정확한 Object Detection임을 보여주고 있습니다.
6. 마치며
YOLO는 CNN을 1번만 통과하는 새로운 구조를 제안하며 기존 Object Detection 알고리즘보다 속도 측면에서 비약적인 발전을 이루었습니다. 그러나 그리드 단위로 나누어 예측을 하기 때문에 그리드 보다 작은 객체를 잘 잡아내지 못합니다. 이는 IOU를 사용하여 Bounding Box의 후보군을 선정할 때 작은 객체는 적절한 Bounding Box를 가지지 못하기 때문입니다. 뒤에서 다룰 YOLO V2, V3에서 YOLO의 한계점이 어떻게 개선되었는지 살펴보도록 하겠습니다.